Regression model validation
In statistics, model validation is possibly the most important step in the model building sequence. It is also one of the most overlooked. Often the validation of a model seems to consist of nothing more than quoting the R2 statistic from the fit (which measures the fraction of the total variability in the response that is accounted for by the model).
Contents |
R2 is not enough
Unfortunately, a high R2 (coefficient of determination) value does not guarantee that the model fits the data well. Use of a model that does not fit the data well cannot provide good answers to the underlying engineering or scientific questions under investigation. However to increase the precision of the R2, some statisticians suggest that you should use the adjusted R2 to reflect both the number of independent variables in the model and sample size. This is only useful for multiple regression.
Analysis of residuals
The residuals from a fitted model are the differences between the responses observed at each combination values of the explanatory variables and the corresponding prediction of the response computed using the regression function. Mathematically, the definition of the residual for the ith observation in the data set is written
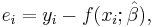
with yi denoting the ith response in the data set and xi the vector of explanatory variables, each set at the corresponding values found in the ith observation in the data set.
If the model fit to the data were correct, the residuals would approximate the random errors that make the relationship between the explanatory variables and the response variable a statistical relationship. Therefore, if the residuals appear to behave randomly, it suggests that the model fits the data well. On the other hand, if non-random structure is evident in the residuals, it is a clear sign that the model fits the data poorly. The next section details the types of plots to use to test different aspects of a model and give guidance on the correct interpretations of different results that could be observed for each type of plot.
Graphical analysis of residuals
There are many statistical tools for model validation, but the primary tool for most modeling applications is graphical residual analysis. Different types of plots of the residuals from a fitted model provide information on the adequacy of different aspects of the model.
- sufficiency of the functional part of the model: scatter plots of residuals versus predictors
- non-constant variation across the data: scatter plots of residuals versus predictors; for data collected over time, also plots of residuals against time
- drift in the errors (data collected over time): run charts of the response and errors versus time
- independence of errors: lag plot
- normality of errors: histogram and normal probability plot
Graphical methods have an advantage over numerical methods for model validation because they readily illustrate a broad range of complex aspects of the relationship between the model and the data.
Quantitative analysis of residuals
Numerical methods for model validation, such as the R2 statistic, are also useful, but usually to a lesser degree than graphical methods. Numerical methods for model validation tend to be narrowly focused on a particular aspect of the relationship between the model and the data and often try to compress that information into a single descriptive number or test result. Numerical methods do play an important role as confirmatory methods for graphical techniques, however. For example, the lack-of-fit test for assessing the correctness of the functional part of the model can aid in interpreting a borderline residual plot. There are also a few modeling situations in which graphical methods cannot easily be used. In these cases, numerical methods provide a fallback position for model validation. One common situation when numerical validation methods take precedence over graphical methods is when the number of parameters being estimated is relatively close to the size of the data set. In this situation residual plots are often difficult to interpret due to constraints on the residuals imposed by the estimation of the unknown parameters. One area in which this typically happens is in optimization applications using designed experiments. Logistic regression with binary data is another area in which graphical residual analysis can be difficult.
See also
References
External links
- How can I tell if a model fits my data? (NIST)
- NIST/SEMATECH e-Handbook of Statistical Methods (Accessed September 2011) ,
This article incorporates public domain material from websites or documents of the National Institute of Standards and Technology.